
Fire Max 11を買いました_私のデジタル世界メモⅡ

ミラーリングとキャスト_私のデジタル世界メモⅢ

これはかなり限られた範囲の記事である。 自宅でルーターでWiFiを設定することを前提として、Fire TVか、 Chromecast with Google TV ...
GPT-4oとGeminiー新・生成AIの世界

私は「生成AIを利用する」という記事で、「自然言語を利用する生成AIの用途として、①検索し説明してもらう、②文書の生成と修正、③長文の要約・翻訳が考えられるが、①はChat GPTで、②はCopilotを利用しよう、③はCl ...
四十雀の巣立ちとお喋り

先週の土日(2024/05/18、19)、家にいると、四十雀のヒナが入っている巣箱や巣箱が架かっている樹木近辺が、可愛い小鳥のさえずりで騒々しい。よく見ると四十雀が4匹飛び回っている。親2匹+子2匹だろう。2匹はときど ...
人生の短さについて_を読む

※修正中です
書誌人生の短さについて:セネカ(光文社古典新訳文庫)
備忘録出版社や解説者の紹介人生は浪費すれば短いが、過ごし方しだいで長くなると説く表題作。逆境にある息子の不運を嘆き悲しむ母親を、みずからなぐさ ...
愚論・戯れ言日録とは_JOKE・冗句・ぼやき・雑言から繋がる世界

これから折々の所感を、無味乾燥な「日々雑感」という「カテゴリー」から抜けだし、「愚論・戯れ言(ざれごと)日録」として記述しようと思う。「愚論」は自らの言表を卑下するわけだがこれはそこそこににして抜け出すことにし、「戯れ言」に ...
弁護士が取り組むこれからの法律事務

弁護士の仕事について、弁護士法3条は「弁護士は、当事者その他関係人の依頼又は官公署の委嘱によつて、訴訟事件、非訟事件及び審査請求、再調査の請求、再審査請求等行政庁に対する不服申立事件に関する行為その他一般の法律事務を行うこ ...
今求められる問いと質問

参考図書
Q思考:ウォーレン・バーガーA More Beautiful Question: The Power of Inquiry to Spark Breakthrough Ideas (English Editio ...
身心を平静に保つ簡易な運動
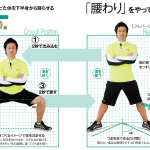
しばらく前までは、私は運動というとダイエットのためと考えていたが、さすがに年齢を重ねると、身心を平静に保つことが運動の目的だということが分かってくる。運動の内容も簡易なものでOKだ。
「東大が考える100歳 ...
四十雀が来た

家の庭の木に古ぼけた巣箱がある。子どもが小さいときに設置したか、孫のときか、それも定かではないが、随分昔に、鳥が巣立ったが、それ以来しばらく居着かなかった記憶がある。 最近、電線から2匹連れの四十雀がよく見ている ...